[DBMS] 커넥션 풀, 시퀀스, SELECT COUNT(*)
1. 커넥션 풀(Connection Pool)
커넥션 풀(Connection Pool)은 데이터베이스 연결을 재사용할 수 있도록 관리하는 리소스 풀입니다. 데이터베이스와의 연결은 시간과 자원을 많이 소모하는 작업이기 때문에, 애플리케이션의 성능과 효율성을 향상시키기 위해 커넥션 풀을 사용합니다. 커넥션 풀을 사용하면 미리 정의된 수의 데이터베이스 연결을 풀에 보관하고, 애플리케이션이 데이터베이스에 접근해야 할 때마다 이 풀에서 연결을 빌려 사용한 뒤 반납하는 방식으로 작동합니다.
커넥션 풀의 주요 특징 및 이점
- 성능 향상: 애플리케이션이 데이터베이스 연결을 필요로 할 때마다 새로운 연결을 생성하는 대신, 미리 생성해둔 연결을 재사용함으로써 시스템 리소스의 낭비를 줄이고 성능을 향상시킵니다.
- 자원 관리: 커넥션 풀은 동시에 활성화될 수 있는 최대 연결 수와 같은 데이터베이스 리소스의 사용을 효율적으로 관리합니다.
- 확장성: 애플리케이션이 처리해야 하는 요청의 양이 증가함에 따라, 커넥션 풀을 사용함으로써 더 많은 요청을 더 효율적으로 처리할 수 있습니다.
- 안정성: 커넥션 풀은 연결의 유효성 검사, 연결의 자동 회복 등을 관리하여 데이터베이스 연결의 안정성을 높입니다.
커넥션 풀 작동 방식
- 초기화: 애플리케이션 서버가 시작될 때, 커넥션 풀은 설정에 따라 정해진 수의 데이터베이스 연결을 생성하고 풀에 저장합니다.
- 연결 사용: 애플리케이션이 데이터베이스 연결을 요청하면, 커넥션 풀은 풀에 있는 유효한 연결 중 하나를 제공합니다.
- 연결 반환: 애플리케이션이 작업을 마치고 데이터베이스 연결을 더 이상 사용하지 않게 되면, 연결을 커넥션 풀에 반환합니다. 이 연결은 다음 요청이 있을 때 다시 사용될 수 있습니다.
- 연결 관리: 커넥션 풀은 연결의 유효성 검사, 유휴 연결 관리(너무 오랫동안 사용되지 않은 연결 종료), 필요에 따라 새로운 연결 생성 및 불필요한 연결 제거 등을 수행합니다.
사용 시 고려 사항
- 커넥션 풀의 크기를 적절히 설정하는 것이 중요합니다. 너무 많은 연결은 리소스 낭비를 초래할 수 있으며, 너무 적은 연결은 동시 요청 처리 능력을 제한할 수 있습니다.
- 대부분의 애플리케이션 서버와 데이터베이스 관리 시스템은 커넥션 풀을 위한 내장 지원 또는 외부 라이브러리를 제공합니다. 예를 들어, Apache Tomcat, JBoss, Spring Framework 등이 있습니다.
2. 시퀀스(Sequence)
데이터베이스에서 시퀀스(Sequence)는 특정 규칙에 따라 순차적으로 증가하거나 감소하는 일련번호를 생성하는 객체입니다. 시퀀스는 주로 테이블의 기본 키(Primary Key) 값을 자동으로 생성하기 위해 사용되며, 이를 통해 유니크한 값을 보장받을 수 있습니다. 각 시퀀스는 데이터베이스 내에서 고유하며, 하나 이상의 테이블에서 공유하여 사용할 수 있습니다.
시퀀스의 주요 특징:
- 자동 증가: 시퀀스는 미리 정의된 규칙에 따라 자동으로 값을 증가시킵니다. 일반적으로 1씩 증가하지만, 사용자가 증가 폭을 직접 설정할 수도 있습니다.
- 유니크한 값 생성: 시퀀스를 사용하면 중복 없이 유니크한 값을 생성할 수 있습니다. 이는 테이블의 기본 키나 유니크 키로 사용될 때 중요합니다.
- 동시성 관리: 여러 사용자나 트랜잭션이 동시에 시퀀스 값을 요청할 때도 각각 다른 값을 반환합니다. 이를 통해 데이터의 일관성과 정확성을 유지할 수 있습니다.
- 성능 최적화: 시퀀스는 데이터베이스 성능 최적화에 기여합니다. 특히, 대량의 데이터를 빠르게 삽입해야 할 때, 미리 시퀀스 값을 생성해 두면 테이블의 기본 키 생성에 따른 성능 저하를 방지할 수 있습니다.
시퀀스 생성 및 사용:
시퀀스의 생성 및 사용 방법은 데이터베이스 시스템마다 약간씩 다를 수 있지만, 일반적으로 다음과 같은 SQL 문법을 사용합니다.
-- 시퀀스 생성
CREATE SEQUENCE 시퀀스_이름
START WITH 초기값
INCREMENT BY 증가량
MINVALUE 최소값
MAXVALUE 최대값
CYCLE | NOCYCLE CACHE | NOCACHE; -- 시퀀스 값 얻기
SELECT 시퀀스_이름.NEXTVAL FROM dual; -- 시퀀스 값 설정
SELECT 시퀀스_이름.CURRVAL FROM dual;
2.1) 시퀀스 생성 예제
CREATE SIQINCE 시퀀스명; >>SQL 명령문으로 입력하면 시퀀스가 생성된다.

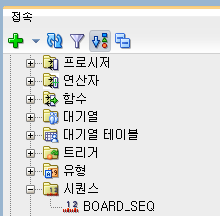
명령문을 입력한 접속창에서 시퀀스 탭을 열어보면 생성된 시퀀스를 확인 할 수 있다.
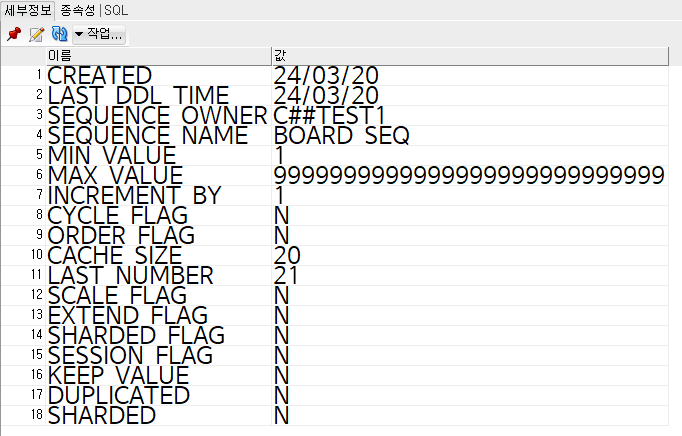
CREATE SIQINCE 시퀀스명; >>으로만 입력해도 나머지 값들이 디폴트 값으로 설정되어 사용할 수 있다.
3. DBMS resultset에서 저장된 데이터 크기를 알 수 있는 메서드가 있어 ?
데이터베이스에서 ResultSet 객체를 통해 조회한 데이터의 크기를 직접적으로 알려주는 메서드는 없습니다. ResultSet 객체는 데이터베이스의 결과를 나타내는데, 데이터베이스에서 데이터를 읽어올 때 일반적으로 서버와 클라이언트 간의 네트워크 트래픽을 최소화하기 위해 한 번에 모든 데이터를 메모리에 로드하지 않습니다. 따라서, ResultSet 객체를 통해 데이터의 전체 크기를 알 수 있는 직접적인 메서드는 제공되지 않습니다.
그러나, 데이터의 크기를 알고 싶은 경우에는 다음과 같은 방법들을 사용할 수 있습니다:
- 전체 행 수 계산: ResultSet을 순회하면서 행의 수를 세는 방법으로 데이터의 '크기'를 얻을 수 있습니다. 이 방법은 매우 비효율적일 수 있으며, 특히 큰 데이터셋의 경우 많은 시간이 소요될 수 있습니다.
int size = 0; //자바 코드
if (resultSet.last()) {
size = resultSet.getRow();
resultSet.beforeFirst(); // 커서를 다시 초기 위치로 이동
}
- SELECT COUNT(*) 쿼리 사용: 데이터의 크기를 알고 싶다면, 해당 테이블에서 SELECT COUNT(*) FROM table_name과 같은 쿼리를 실행하여 전체 행의 수를 빠르게 얻을 수 있습니다. 이 방법이 가장 효율적이긴 하지만, 현재 ResultSet의 필터링 조건이나 정렬 상태를 반영하지 않을 수 있습니다.
- 데이터 사이즈 추정: 실제로 ResultSet에서 특정 컬럼의 데이터 크기를 알고 싶은 경우, 데이터를 순회하며 각 행의 해당 컬럼 데이터 크기를 계산할 수 있습니다. 이는 BLOB, CLOB, 문자열 또는 바이너리 데이터의 크기를 추정할 때 유용할 수 있습니다.
결론적으로, ResultSet에서 제공하는 메서드를 통해 직접적으로 저장된 데이터의 '크기'를 알 수는 없으며, 용도에 맞는 방법을 선택하여 사용해야 합니다. 데이터의 크기를 알고 싶은 목적에 따라 적절한 접근 방식을 선택하는 것이 중요합니다.
쿼리의 결과는 단일 컬럼, 단일 행이므로, 이 경우 컬럼명 대신 컬럼의 인덱스를 사용할 수 있습니다. 컬럼 인덱스는 1부터 시작합니다. 따라서 ResultSet을 .getInt(1)로 받아오면 된다.
COUNT(*)의 결과는 항상 존재하기 때문에 if(rs.next()) 검사가 항상 true를 반환합니다.
